1. Summary
We have created optimized parallel implementations of the deduplication module in CloudFS (a hybrid cloud-backed local file system, developed in 18-746: Storage Systems), that makes use of Rabin fingerprinting for chunking on a multi-core CPU platform, and performed a detailed analysis of the system’s performance characteristics. We have also explored using a GPU for accelerating the computation of the Rabin fingerprinting algorithm and implemented a naive version using CUDA.
2. Background
2.1. CloudFS and deduplication module
In file systems, a common way to avoid redundant computations and storage is to perform deduplication on the data. Cloudfs is one such file system which we developed as a part of 18-746 (Storage Systems) class which performs deduplication across files. The deduplication module detects duplicate content during any write/update operation in the filesystem, using a popular content-based chunking algorithm - The Rabin fingerprinting algorithm. The deduplication module at a high level performs the following 3 operations :
- It reads the stream of input data in a buffered manner
- Computes the chunk boundaries using the Rabin fingerprint algorithm
- Identifies chunks as the data between the chunk boundaries and computes an MD5 hash over each chunk.
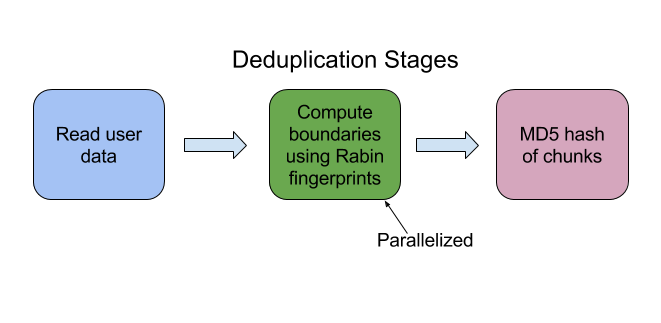
Figure A: Stages in deduplication module
2.2. Rabin fingerprinting
It detects boundaries of these chunks in the input data based on the content. A chunk is the data between 2 such boundaries. This may lead to variable sized chunks.
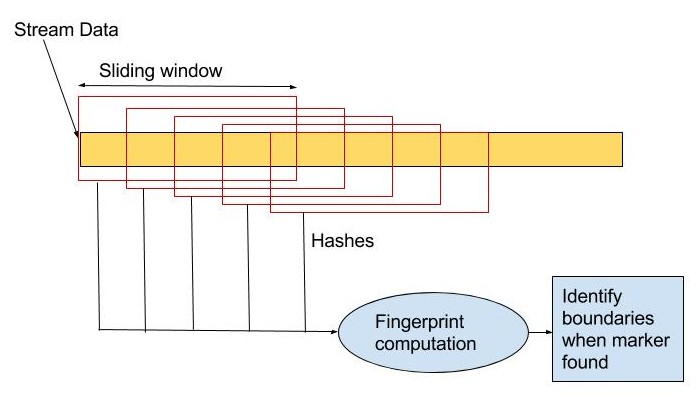
Figure B: Basic working of Rabin Fingerprinting algorithm
As seen in Figure B, the algorithm computes fingerprints over a sliding window of data. The fingerprint calculation involves polynomial division of a polynomial of degree w-1 for a w bit sequence, with an irreducible polynomial of degree k. This is a very computationally intensive operation.
Data structures:
The state of the rabin algorithm is maintained by the rabinpoly library structure :
struct rabinpoly {
u_int64_t poly; // Actual polynomial
unsigned int window_size; // in bytes
unsigned int avg_segment_size; // in KB
unsigned int min_segment_size; // in KB
unsigned int max_segment_size; // in KB
u_int64_t fingerprint; // current rabin fingerprint
u_int64_t fingerprint_mask; // to check if we are at segment boundary
u_char *buf; // circular buffer of size 'window_size'
unsigned int bufpos; // current position in ciruclar buffer
unsigned int cur_seg_size; // tracks size of the current active segment
int shift;
u_int64_t T[256]; // Lookup table for mod
u_int64_t U[256];
};
Operations:
Following key operations are supported by the dedup library:
rabin_init() : initialises the rabinpoly struct and constructs lookup buffers
compute_rabin_segments() : Performs the actual computation of finding the markers/chunk boundaries
rabin_reset(): Use this to use the same rabinpoly struct for a different file
rabin_free(): Called at the end to free all resources allocated by rabin_init()
Input and Output to the algorithm:
- Input :
Pointer to the input datastream whose chunk boundaries are to be found - Output :
List of marker positions indicating chunk boundaries in input data, and number of markers found
2.3. Motivation for parallel dedup (Computationally expensive part)
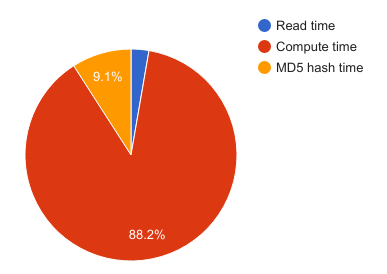
Figure C : Breakdown of the execution times in different sections of the deduplication module. About 88% of dedupe time is spent in computation.
As seen in Figure C, on observing the execution times of various sections in the deduplication module, it was observed that majority of the time was spent in the Rabin Fingerprint function, whereas read and MD5 computation time was much lesser. Thus, The computation time in this case is greater than the I/O or bandwidth latency of the filesystem and it is thus, compute-bound. Hence, content based chunking algorithm will definitely benefit from parallelism as it will directly improve the file system throughput. Our goal was to improve reduce the execution time of the computation by parallelising it.
2.4. Dependencies in the program that would affect parallelism
The computation of the fingerprints in the algorithm is optimized by using the fingerprint of the previous window to calculate the fingerprint of the current window. Hence, it could be challenging to make it data parallel. Since different threads would work on different sections of data, it could be challenging to compute fingerprint especially for windows that cover data from 2 threads.
3. Approach
3.1. Parallel Rabin fingerprinting algorithm
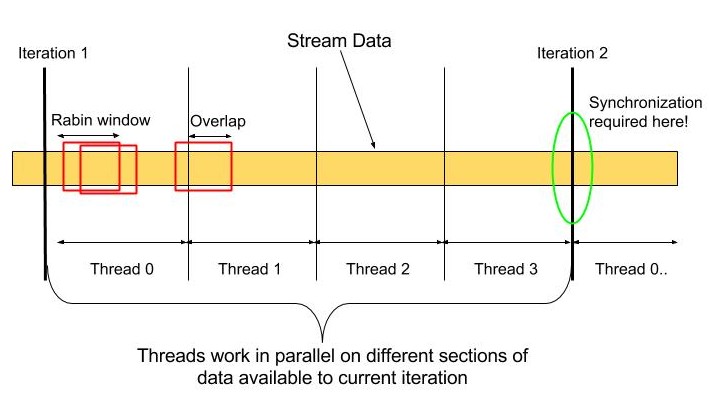
Figure D : Idea of parallelism in Rabin fingerprinting algorithm
We employ parallel threads to work on different chunks of the input data stream read by a single iteration of the dedup module in CloudFS. Each thread performs Rabin fingerprinting on its chunk using local rabinpoly_t state. As mentioned above, there is dependency across thread boundaries for an optimized computation in the sliding window fingerprinting. However, to parallelize the algorithm, we can give up on this optimization across thread boundaries by having each thread compute the rabin fingerprint for up to (WINDOW_SIZE-1) bytes in the subsequent thread’s chunk space. The small amount of redundant WINDOW_SIZE computation is not an overhead due to potential speedup possible in the large data stream processing. The “Overlap” in the figure shows one such region where the synchronization requirement can be overcome by this extra computation. However, since the last thread does not have future input data available to it, it cannot do the same, and hence must synchronize with the first thread that will process the subsequent data in the next iteration from the dedup module. This can be done using #omp pragma barrier in the naive approach, but this synchronization can be optimized further.
3.2. Environment
Technologies
- CPU-parallelism: OpenMP
- GPU-parallelism: CUDA
- Test framework: Python
- CloudFS: C, C++, Python, libs3, tornado server
Target hardware
- 8-core (hyperthreaded) 3.20 GHz Intel Xeon i7 processors
- NVIDIA GeForce GTX 1080 GPUs
Machines used
GHC41.GHC.ANDREW.CMU.EDU and GHC45.GHC.ANDREW.CMU.EDU
3.3. Mapping the problem to target parallel machines
- CPU parallelism:
We used 16 OpenMP threads to populate the 16 execution contexts of the 8-core 2-way multithreaded CPU on GHC. Each thread worked on a 1 KB section of the input buffer (in total, a 16 KB buffer is read from the file iteratively by the dedup module and each thread is supplied a 1 KB chunk of the data). - GPU parallelism:
We used 2048*20 CUDA threads to populate the 2048 execution contexts of the 20-core GTX 1080 GPU on GHC. Each thread worked on a 1 KB section of the input buffer (in total, a 2048*20 KB buffer is read from the file iteratively and each thread is supplied a 1 KB chunk of the data).
3.4. Change in original serial algorithm to benefit from parallelism
Original serial algorithm (rabin_segment_next() API of the rabin fingerprint library) invoked by the dedup module of CloudFS processes the input buffer and returns as soon as it detects a marker. It is an iterative function that maintains the computation state within the rabinpoly_t structure passed to it across invocations. In order to implement a parallel version of rabin fingerprinting to detect segment boundaries, we need to implement a one-time call that processes a huge batch of data and determines the marker positions in the data stream, by employing multiple threads to work on different sections of the data stream. Hence, we implemented a better parallelizable version of the serial algorithm (compute_rabin_segments_serial() and its later counterparts- compute_rabin_segments_cpu() for CPU-parallel version and compute_rabin_segments_gpu() for GPU-parallel version). These versions simply process the entire buffer and returns all marker positions detected in the entire sequence. This enables employing multi-core as well as data-parallelism in the function versions.
3.5 Iterations of optimization
- Initially we started out with the goal of parallelising the deduplication library wherein each thread performed all the 3 steps of reading, rabin fingerprint computation and MD5 hash computation.
- However, we observed that there was negligible speedup as the program had become bandwidth bound due to a high number of read requests coming from each thread concurrently. In order to have fewer number of reader threads, we used separate threads for reading and performing computation.
- However, we still did not get a good speedup as the access pattern of various threads reading at different offsets in the file was bad. There was little locality and hence, the local filesystem performance during reads was also affected. This was confirmed by the timing traces of the sequence of read() calls.
- On making observations about the performance bottlenecks, we realised that the compute phase took maximum amount of time and would benefit the most from parallelism.
- Hence we proceeded to parallelise the compute phase and keep the reads and MD5 computations serial.
- For the CPU parallel version, we performed many optimizations to minimise synchronisation overheads by removing barriers. We also changed few access patterns and structures to leverage better locality. These optimizations finally led us to the current CPU parallel version.
- For GPU version, we simply implemented a basic naive version and did not have the time to perform GPU specific optimizations.
3.6 Starter codebase
CloudFS project that we developed in our 18746 (Storage Systems) class, a single threaded hybrid FUSE-based file system. (Project repository can be shared on demand, required to be private by course guidelines).
4. Results
4.1. Measuring performance
We have measured the following execution times for various code sections for the serial, CPU parallel and GPU parallel versions of the Rabin hash algorithm :
- Total time for deduplication to happen
- Time to read from data stream in the algorithm
- Time to do the actual computations of Rabin Fingerprinting algorithm
- Time to compute MD5 hash algorithm
We have also measured the speedup for the Rabin fingerprint algorithm compute time as well as the speedup of the entire deduplication module with respect to the serial implementation.
4.2. Experimental setup: (input sizes, generation of requests)
We performed experiments by invoking the deduplication module in 2 ways :
- Directly invoking deduplication on a file created through a test
- Invoking the deduplication module by performing writes to CloudFS. Upon write requests, CloudFS invokes the deduplication module.
We performed various tests by varying the write sizes from 4KB to 512KB. We also experimented with different file sizes (which can be controlled based on the number of writes) ranging from 1 MB to 1GB.
The writes requests consisted of uniform as well as random data which were invoked by various tests. The tests invoke the serial, CPU parallel and GPU parallel versions of the deduplication module and the above measurements are taken.
4.3. Graphs of speedup or execute time
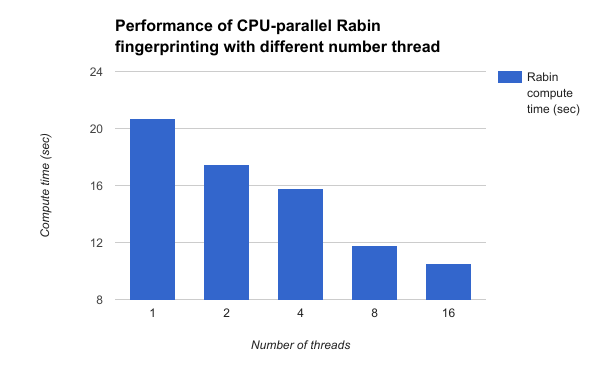
Figure 3.1: Compute time vs Number of threads
(Rabin compute time for 16 KB writes on GHC using OpenMP)
Figure 3.1 shows the execution times of only the compute portion of the Rabin fingerprint algorithm by varying the number of threads. We observe a linear drop in the execution time for the CPU Parallel version, when changing the number of threads from 1 to 16.
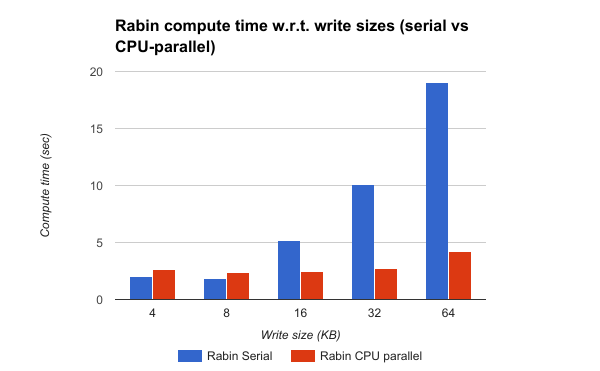
Figure 3.2: Compute time vs Write Size
(Rabin compute time for 16 KB writes on GHC using OpenMP)
Since 16 threads gave the best performance, we fixed the number of threads = 16 for further observations. Figure 3.2 shows the execution times of only the compute portion of the Rabin fingerprint algorithm by varying the size of individual writes from 4KB to 64 KB. It is observed that as the write size increases, the serial version starts performing poorly whereas the parallel version is very fast. Thus, the speedup goes on increasing as the write size increases.
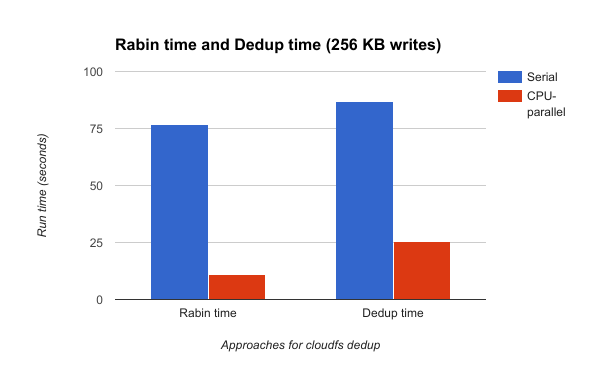
Figure 3.3: Rabin compute time and Deduplication module compute time: serial vs parallel (Write size = 256 KB)
TBD
Rabin compute time with 16 threads on GHC (1KB per thread using OpenMP)
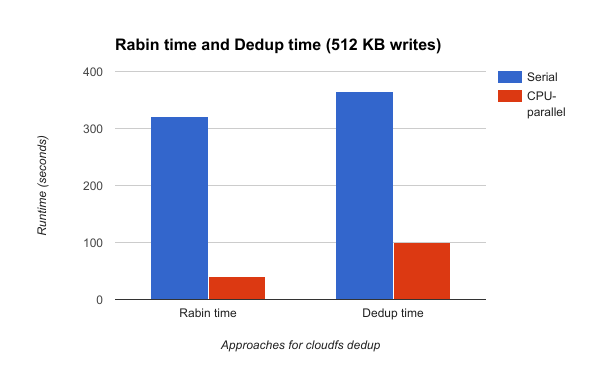
Figure 3.4: Rabin compute time and Deduplication module compute time: serial vs parallel (Write size = 512 KB)
Rabin compute time with 16 threads on GHC (1KB per thread using OpenMP)
The graphs in Figure 3.3 and 3.4 show the execution times of the Rabin computation alone as well the entire deduplication module. Measurements are taken for write sizes 256 KB and 512 KB for the serial and cpu parallel versions. It is observed that for writes of size 256 KB, the cpu parallel version gives a speedup of 7x for the Rabin computation and a total speedup of 3.5x for the entire deduplication module, over the serial version. Similarly, for write sizes 512 KB, the cpu parallel version gives a speedup of 8x for the Rabin computation and a total speedup of 3.6x for the entire deduplication module over the serial version.
Analysis
1. Rabin computation module is able to achieve decent speedup because of the cpu-parallel algorithm, but is not able achieve linear speedup due to the synchronization required between last thread and first thread (due to data dependency of Rabin fingerprinting) which is a bottleneck. (we confirmed this using fine-grained timing traces in the code).
2. The entire deduplication module is not able to achieve a perfect speedup because the MD5 computation phase after the rabin computation phase is the serial portion which is not parallelized. We can further look into optimizing the other phases in order to see a proportional speedup in dedup module. This should also help us improve the file system’s write throughput.
3. The increasing speedup with increase in write sizes show that there is a tremendous potential to parallelize it using more resources and reduce the execution time. Since we have already explored the multi-core parallelism, we decided to go with GPU parallelism for large write sizes.
4.4. Analysis: limitations in speedup and breakdown of execution time
-
Some data dependencies:
As mentioned earlier, there is data dependency across thread boundaries of the last and first thread (across iterations of invocations to compute_rabin_segment_cpu). Specifically, the first thread needs to read data from the last thread’s local computation. -
Communication/synchronization overhead:
The above mentioned dependency can be satisfied by having the last thread store its local computation (rabinpoly_t’s buf, bufpos, fingerprint and cur_seg_size fields) in a global space, from which the first thread can read in next iteration. However, this is a race condition in which the last thread can potentially overwrite the global state before the first thread reads in the previous iteration state for it to start correctly. This can cause incorrect results and thus requires the barrier synchronization so that next iterations’ writes by last thread do not occur before the previous iterations’ reads by first thread. We further optimized this barrier synchronization by using some temporary space to copy into, outside the pragma omp parallel block. -
Some divergence/workload imbalance:
Given the data dependency requirements of the algorithm for correctness, the first and last threads essentially have to perform slightly more amount of work in each iteration. Thus, we see some workload imbalance despite high level of data parallelism in most section of the compute function. -
Locality:
In one of our earlier implementations, the pattern of accesses of the rabinpoly_t state by multiple threads was randomly strayed in memory, which led to poor locality. We overcame this by re-structuring some portion of the code and improving locality of accesses.
CPU parallel version:
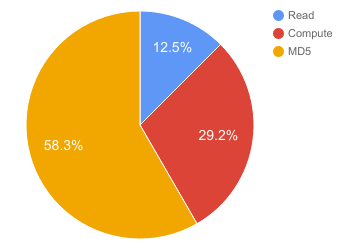
Figure 3.5: Breakdown of execution times of various steps during CPU parallelization of Rabin fingerprinting algorithm
Dedup and rabin compute time with 16 threads on GHC (1KB per thread using OpenMP)
After implementing the parallel rabin compute, we found that now, the serial MD5 hashing phase is the slowest component in the CloudFS dedup module. This makes sense since the MD5 hashing is performed on all segments returned by the compute_rabin_segments_cpu() function and the MD5 library calls scan the buffers passed to it. Thus, as we increase write sizes, the compute speedup goes on increasing and the MD5 hash starts becoming the bottleneck in the dedup module. It would be interesting to either think of parallelizing the hashing, or integrating the MD5 hashing of segments along with the compute_rabin_segments_cpu() function. That may help increase dedup module speedup and result in overall increase in file system write throughput.
GPU parallel version:
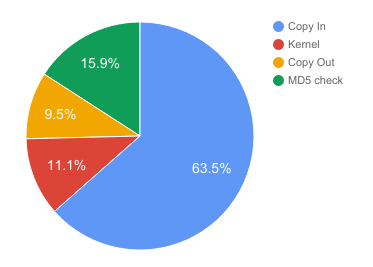
Figure 3.6: Breakdown of execution times of various steps during GPU parallelization of Rabin fingerprinting algorithm
Cloudfs dedup time with 2048*20 CUDA threads on GHC (1KB per thread)
A naive version of GPU parallelization algorithm, similar to the CPU parallel algorithm has been implemented using CUDA. For the GPU parallel implementation, memory needs to be allocated on the GPU and data transfer needs to be done between CPU and GPU. After allocating memory on the GPU, there are 4 phases in the GPU parallel implementation :
- Copy In phase to copy user buffer from CPU to GPU
- Kernel launch which actually performs the computation on GPU cores
- Copy Out phase to copy results from GPU to CPU
- MD5 hash computation of the chunks on CPU
Figure 3.6 shows the breakdown of the execution times of these phases. It is observed that the copy in phase takes the majority of the time and this is prevents the GPU parallel version to achieve a good speedup despite a high number of computing resources.
Moreover, the GPU implementation speedup is not linear since it is memory bandwidth bound for large thread counts since all these threads simultaneously issue multiple loads and stores to different addresses. The memory accesses should be more streamlined to reduce this bottleneck.
Some possible GPU specific optimizations:
- GPU memory accesses can be more streamlined by having separate threads that perform loads into shared memory, threads that execute the kernel and those which update device memory state from the shared memory state. We can pipeline the execution kernel with the load/store threads. This will help alleviate the bandwidth limitations by producing controlled memory traffic, but still maintaining a decently high degree of data parallelism among the CUDA threads.
- Hiding CPU-GPU data transfer overheads by overlapping copying and execution times using different GPU Streams (cudaMemcpyAsync can be used). We need to use pinned memory on host (via cudaMallocHost) since cudaMemcpyAsync only works with pinned host memory (so that OS does not swap out the memory while it is being asynchronously copied to device memory).
- Hiding GPU memory allocation overheads by reusing device global memory across rabin library calls has already been implemented and is useful to cut down unrequired allocation times per call.
- Efficient use of GPU shared memory for lookup buffers, rabinpoly window buffer, fingerprint and other state can help save some expensive device memory accesses and localize the shared state among threads with lower latency shared memory reads.
5. References
- Samer Al-Kiswany, Abdullah Gharaibeh, Matei Ripeanu, GPUs as Storage System Accelerators, IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 24, NO. 8, AUGUST 2013.
- Udi Manber, Finding Similar Files in a Large File System, USENIX Winter 1994 Technical Conference Proceedings, Jan. 17-21, 1994, San Francisco, CA.
- Pramod Bhatotia, Rodrigo Rodrigues, Akshat Verma, Shredder: GPU-Accelerated Incremental Storage and Computation
- Rabin fingerprinting library: https://github.com/joeltucci/rabin-fingerprint-c
- Rabin fingerprinting original documentation by Michael O Rabin: http://www.xmailserver.org/rabin.pdf
- Rabin fingerprinting original paper (Finding Similar Files in a Large File System):
- http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.12.3222&rep=rep1&type=pdf
- LBFS usecase for Rabin fingerprinting: https://github.com/fd0/lbfs/tree/master/liblbfs
- Rabin GPU for network packet dedup: https://github.com/aimlab/rabinGPU
- OpenMP: https://computing.llnl.gov/tutorials/openMP/
- CUDA: https://docs.nvidia.com/cuda/cuda-c-programming-guide/#compute-capabilities